

Unicode, yaygın bir biçimde kabul gören bir karakter kodlama uygulamasıdır. Microsoft tarzı yazılımlar, öncelikle Unicode kullanmaktadır. Bizler de farkında olmadan, Unicode kullanıyoruz. Temel anlamda, “bilgisayarlar sadece sayı biçimleriyle alakalıdır. Harfler ve diğer karakterlerin her biri için bir sayı atanarak depolama yöntemi uygulanır.
Unicode icat edilmeden öncesinde, bu sayıları atama açısından yüzlerce farklı kodlama sistemi entegre olmaktaydı. Tek bir kodlama sistemi yeteri karakter içeremez. Sık sık karşılaşan sorunların başında ise bunlar gelmekteydi.
Eski bir kodlama biçimi kullanıyorsanız eğer, yazı biçiminiz dünyanın herhangi bir bölgesine dair birinin kullandığı yazı tipiyle orantılıdır. Sahip olduğunuz yazı tipinde ise başka bir yer ile birebir aynı kod noktasında hareket orantısı genellikle çakışabilir. Dosyalarınız uyumsuz olsa bile. Unicode, her bir karakter açısından eşi benzeri olmayan bir numara sağlamaktadır. Bu nedenle Unicode kullanıyorsanız herhangi bir sorun ile karşı karşıya kalmazsınız. Dosya belgeriniz herhangi bir U+0278‘u gibi kodları çağırıyorsa karakterin ne olması gerektiği veya herhangi bir bilgisayar programı için açık bir şekilde ön planda olacaktır.
Bu kod birimleri genellikle, 0’dan 16’ya kadar sayılarla tanımlanabilen, düzlem adı ile adlandırılan 17 farklı bölüm üzerinden ayrılmıştır. Her düzlemde 65.536 kod noktası bulunmaktadır. İlk düzlem, 0, en sık kullanılan karakterleri içerebilmektedir ve Temel Çok Dilli Düzlem (BMP) olarak söylenebilmektedir.
Kod Şematiği
Kodlama şematikleri, bir karakter üzerinden bir düzlem yönünden konumlandırıldığı yer için bir koordine sağlamak açısından kullanılan kod birimlerinden oluşmaktadır.
Örneğin UTF-16’yı baz almak gerekir ise, her 16 bitlik sayı bir kod birimi olmaktadır. Kod birimleri genellikle kodlama noktalarına dönüştürülebilmektedir. Örneğin, düz not sembolü olarak “♭”, U+1D160 kod noktasına sahiplik yaparken ve Unicode standardının (Ek İdeografik Düzlem) ikinci düzleminde yer alır. 16-bit kod birimleri U+D834 ve U+DD60 kombinasyonu kullanılarak kodlanır.
BMP açısından ise, kod noktalarının ve kod birimlerine dair değerler genellikle aynıdır. Bu yöntem ise, çok fazla depolama alanı kazandırabilen UTF-16 için ayrıca bir kısa yol sağlar. Bu karakterleri temsil etmek açısından yalnızca bir 16 bitlik bir sayı kullanması gerekebilmektedir.
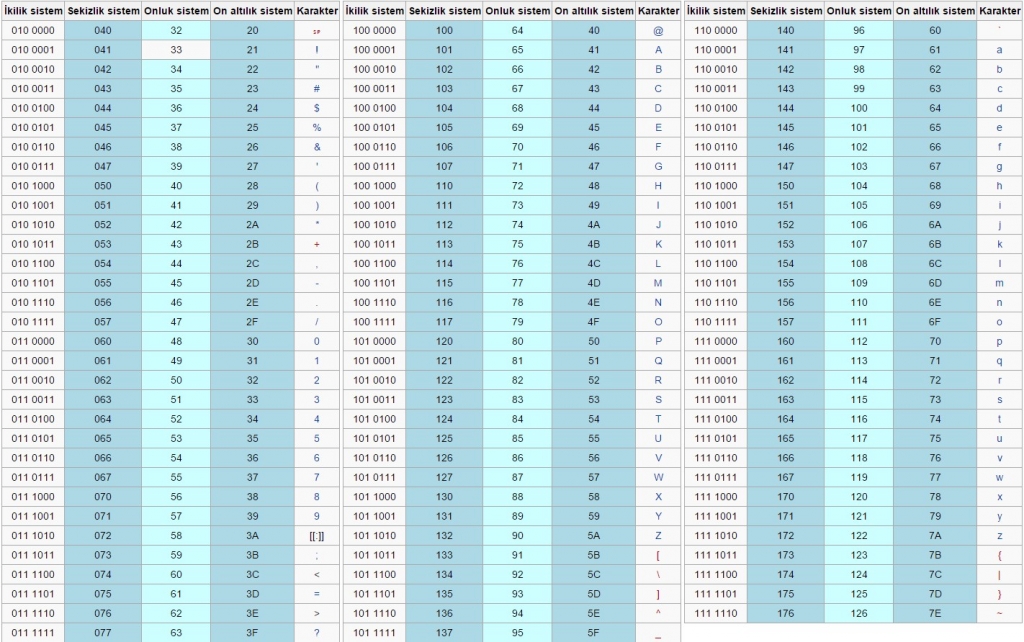
Kullanım Yöntemi
Unicode standartlarının belirlediği ve küçük bir biçimde karakteristik tanımlanmış ve bu değerlere sahiplik yaptığı zamanlarda ortaya çıktı. O zamanlar içerisinde, ihtiyaç duyulacak tüm karakterler biçimlerini kodlama yönünden 16 bit kapasitenin fazlasıyla yeterli olabileceği kanaati getirilmekteydi. Bu tarz içerisinde akılda kalıcı bir şekilde yer alınarak Java, UTF-16’yı kullanabilecek bir biçimde uygulamaya yer verilip tasarlanmıştır. Char veri kodlaması ilk başlarda 16 bitlik bir Unicode kod yerleşkesini temsil etmek açısından kullanıldı.
Bununla birlikte Java SE kodlaması, karakteristik bir kod biçimini de temsil etmektedir. Kod birimine dair değerlerin kod noktasıyla aynı biçimde yer aldığından, Temeli aktif Çok Dilli Düzlem içerisinde karakterleri temsil etme yönünden çok az fark ortaya koymaktadır. Fakat, diğer düzlemlere dair karakterler yönünden ise iki karaktere ihtiyaç duyulduğu zamanlarda olmuştur.
Akılda yer edinmesi gereken bir konu ise, tek bir char yazılımı veya veri türünün, benimsenen tüm Unicode karakterlerini temsil altında tutamayacağı da gözler önüne serilmesi gerekmektedir.
Neden Kullanmalı?
Unicode yazılımı, Fransızca, Japonca ve İbranice vb. birden çok komut dosyası içeriği ile birlikte verileri desteklemektedir. Farklı durumlar içeriğindeki kayıtlar ile birlikte, tek bir raporda birleştirmenize öncelik sağlar. Unicode yazılımının öncesinde, bir bilgisayar üzerinden yalnızca tek bir komut içeriğine bağlı olan işletim sistemleri ile birlikte, kod sayfasına dair yazılı sembolleri işleyebilmekle birlikte görüntüleyebilme imkanı da sunmaktaydı. Örnek vermek gerekir ise, bir bilgisayar Fransızcayı işleyebiliyorsa, Japonca ve İbranice’yi görüntüleyemez.
Unicode, Google Chrome ve Firefox gibi tarayıcılar üzerinde tercih edilebilen bir metin kodlama yöntemi olarakta bilinir. Unicode ayrıca Java teknolojileri yönünden, HTML, XML ve Windows ve Office’te dahili olaraktan yer alır. Unicode, Information Builders gibi ürünlere dair ve Unicode kullanan ve Information Builders gibi ürün hatlarına entegre edilmiş bir biçimde üçüncü taraf tesislere dayanan arabirim açısından sorunsuz bir şekilde de yönetilmesini sağlayabilmektedir.
Bu durumları değerlendirerek, sizlere de makalemizde Unicode yazılımı hakkında bilgi vermeyi amaçlamaktayız.
















